Web Programming
CIS 193 – Go Programming
Prakhar Bhandari, Adel Qalieh
CIS 193
Prakhar Bhandari, Adel Qalieh
CIS 193
Go code is organized into packages - we've been using packages throughout the semester!
All of the files in a package are in the same directory
package main
import (
"fmt"
"strings"
"math/rand"
)
func main() {
fmt.Println(rand.Int())
}To rename an import, simply place the desired name before. This is important when the imported names clash.
import (
"crypto/rand"
mrand "math/rand"
)
What happens if you import into _?
So far, we've limited ourselves to packages included with the Go standard library.
We can use go get to install packages from the internet
The GOPATH environment variable tells the Go tool where your workspace is located.
go get github.com/dsymonds/fixhub/cmd/fixhub
The go get command fetches source repositories from the internet and places them in your workspace

How do you choose what version of a package you want with go get?
Currently, you can't! Thus, there are several unofficial community-led projects to solve the Go versioning problem.
All of these work on a vendor subdirectory and install packages there instead of in the global namespace, $GOPATH/src.
go install a local package and caches it in the pkg directory, similar to `go build`
go list lists the buildable Go packages in the current directory recursively
go doc shows documentation for the provided input, ex:
go doc fmt.Println

$GOPATH/
bin/fixhub # installed binary
pkg/darwin_amd64/ # compiled archives
github.com/...
src/ # source repositories
github.com/
golang/lint/... # used by package fixhub
.git
google/go-github/... # used by package fixhub
.git
dsymonds/fixhub/
.git
client.go
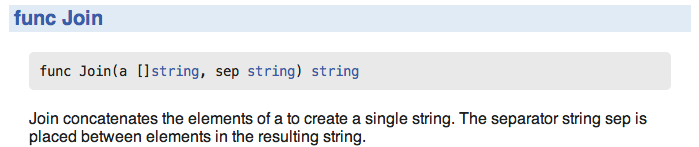
cmd/fixhub/fixhub.go # package mainDoc comments are before the declaration of an exported identifier:
// Join concatenates the elements of elem to create a single string.
// The separator string sep is placed between elements in the resulting string.
func Join(elem []string, sep string) string {These are complete sentences beginning with the exact identifier. Everything public should be documented!
The godoc tool extracts such comments and presents them on the web:
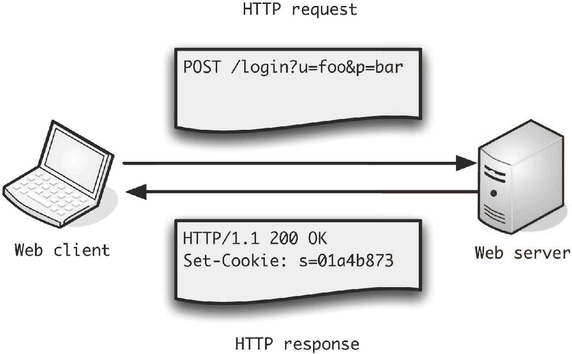
HTTP (Hyper Text Transfer Protocol) is a client-server protocol. Remember that a server is an application that listens for incoming requests from clients, and returns and appropriate response.
When you access a page on the web, you (the client) make an HTTP request to the webserver hosting the page, and you get the HTML from the server as a response.
HTTP is a protocol to communicate on the web
Consists of verbs on resources:
GET Requests
resp, err := http.Get("https://httpbin.org/get")
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)POST Requests
http.Post or http.PostForm.Sending Data
url.Values type
The status code of a response object resp is given by resp.StatusCode
net/http packageTo actually check for HTTP status code errors in Go:
if resp.StatusCode != http.StatusOK {
// http.StatusOK == 200
}APIs, or Application Programming Interfaces, specify how to interact with a piece of software
Lots of services on the web provide APIs that usually communicate data in JSON
Remember JSON?
{
"id": 1,
"name": "A green door",
"price": 12.50,
"tags": ["home", "green"]
}Revisit the previous lecture for how to handle JSON in Go
HTML, or HyperText Markup Language, is a standardized format for the contents of a webpage
HTML documents are made of elements (tags) that have nested content and attributes
Most tags have an opening and closing tag
<a href="http://www.google.com">content</a>
HTML documents form a tree-like structure, with <html> as the root
Since so much data is on the web, and some of it may not be available via a convenient API, web scraping is a means for programmatically extracting data from the web
Web scraping can be done with several languages - what are some benefits of using Go?
There are several techniques and strategies for web scraping
To extract data from a page, you need to be familiar with the structure of the HTML document
<html>
<h1>I am a heading!</h1>
<div>
<p>
<a href="http://www.google.com">Google</a>
</p>
</div>
<div>
<a href="http://www.yahoo.com">Yahoo</a>
</div>
<a href="http://www.bing.com">Outside link</a>
<p>Hi I am a paragraph and I am <strong>bold</strong></p>
</html>
We'll be using the goQuery package
go get github.com/PuerkitoBio/goquery
See the full documentation here
goQuery uses CSS selectors to manipulate HTML documents, inspired by jQuery, a popular Javascript library.
Some examples:
"p" -> Selects all <p> elements "p, a" -> Selects all <p> and <a> elements ".test-class" -> Selects all elements with class="test-class" "#test-id" -> Selects all elements with id="test-id" "p a" -> Selects all <a> elements inside <p> elements "p > a" -> Selects all <a> elements with parent <p>
A more complete guide is here
doc, err := goquery.NewDocument("http://metalsucks.net")
// Error handling
// Find the review items
doc.Find(".sidebar-reviews article .content-block").Each(func(i int, s *goquery.Selection) {
// For each item found, get the band and title
band := s.Find("a").Text()
title := s.Find("i").Text()
fmt.Printf("Review %d: %s - %s\n", i, band, title)
})
Equivalently, we can use range
sel := doc.Find(".sidebar-reviews article .content-block")
for i := range sel.Nodes {
band := sel.Eq(i).Find("a").Text()
title := sel.Eq(i).Find("i").Text()
fmt.Printf("Review %d: %s - %s\n", i, band, title)
}